Technical Blog
Tips & Tricks in OR (Operations Research) Practice

Author
David Gravot
Reading Time
5 minutes
What is Operations Research (OR) and how does it work?
Operations Research (OR) is a science with solid grounds coming from mathematics (graph theory, combinatorial optimization, convex and non-convex geometry …), artificial intelligence (A*, constraint programming), local search and other metaheuristics such as evolutionary methods (Genetic Algorithms), simulated annealing or even nature-inspired methods such as ant-colony or swarm particle.
Today OR Practitioners are spread among a whole spectrum of industries. Most of them are both analysts and modelers/developers. There is not a clear distinction between modelers and developers, since you need to write your model with code! However, OR developers do not only design the model but also link them to the backend application, facilitate the user experience through what-if analysis tools, work closely on the User Interface design to provide what will facilitate the end-users life.

OR practitioners need to consider their end user. This usually ends up being planners.
OR practitioners can be somehow seen as evangelists of all these advanced techniques toolkit with one goal: assist end users in their operations. These users are most of the time known as ‘planners’ who are in charge of creating ‘plans’. For instance, in manufacturing, planners are in charge of building various types of plans : Demand Planning (sometimes mixed with predictive machine learning), S&OP (Sales & Operations Planning), RCCP (Rough Cut Capacity Planning), Mid term planning, Short term planning & scheduling, inventory optimization and real-time scheduling.
Advice #1
Delegate preprocess and save OR practitioner time with what they are better at doing (ie. modeling and testing the optimization.
Highlights, a non-exhaustive list of best practices in OR.
Tips & tricks that may help the OR practitioner to get the best of its work.
Load only necessary data
Usually, data models are far richer than what the optimization actually deals with. There are two alternatives for this: either limit the data model that pulls the information from corporate data silos, or preprocess data to create the scenario to optimize with a restriction of the available input data.
More models during prototyping
One can trust an optimization model only by testing it on a set of relevant data. When data comes late, the risk of creating a math model that might not scale is hidden. That’s why we highlighted the urge of getting relevant data as soon as possible (see §3.1 Data collection). With this assumption, the OR practitioner must come quickly to the point where the complexity of its model can be challenged. For instance, if the model is continuously linear for most of the constraints but one or two specific use cases that imply discretization, it is absolutely critical to retrieve or build a data set that would allow testing this feature.
Advice #2
Use a modeler to build concurrent models during the prototyping phase. Modelers allow much faster prototyping than usual Object Oriented languages, thanks to a dedicated language and test environments. Keep these models up-to-date even if the final code is written in another language.
Re-use assets
As time goes by, at DecisionBrain we build our own libraries that may be reused when creating a new product or starting a project. It’s a good practice that avoids starting from the blank page. It also progressively adds instances to the common library and improves its robustness, which then benefits all the other projects that use it.
More testing during prototyping
Use all available test environments, such as CPLEX/CPO command line . This will allow the OR practitioner to focus on the solve behavior with the ability to change settings without changing the code, analyse the behavior of the engine such as engine presolved models.
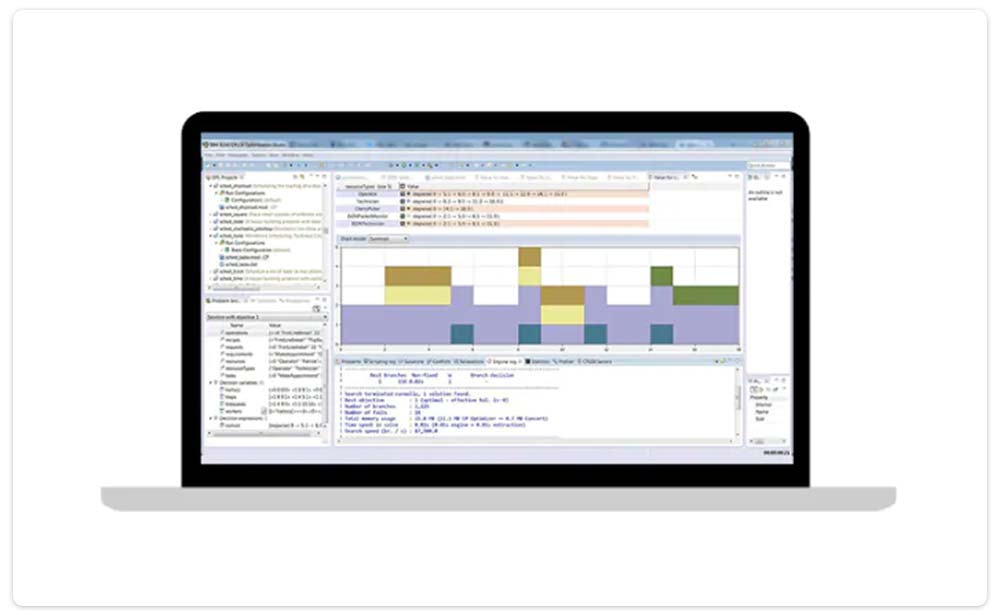
CPLEX utilized for a OR developers application.
Rewrite part of the model
Some models might be mathematically equivalent but the way some constraints are implemented can make a difference. For instance, in a linear problem, avoid getting very long expressions made of tens of thousands of variables. Sometimes, we can see dramatic improvements when switching to a “delta” model. For instance, instead of summing terms from the start of the horizon to the end, you could define a new expression that sums the terms that differ from one period to the next.
Analyze conflicts
High level solvers such as CPLEX / CPO allow the OR practitioner to find a minimal set of conflicts out of the original model. This is very useful to debug mathematical models at an early stage and also detects data errors.
Advice #3
Learn to extract a conflict from an infeasible model and analyze it to understand the root cause. Use a command line when available to get faster hands on the conflict detection.
Document your data and mathematical models
Data models change usually synchronize with the mathematical model. Both models’ descriptions shall be properly documented and maintained all along the project and then during its maintenance. Think of other resources that might jump into the project and replaces the original developer team.
Provides a replay mechanism
Once the application is deployed, optimization jobs are executed on customers’ premises or cloud. What if any job fails or ends up with unexpected results? This behavior needs to be analyzed by the OR developer with the very same context as when it was launched on the production environment.
Advice #4
Use some deployment environment such as DOC OS to retrieve offline a snapshot of the optimization context.
Advice #5
Benchmarking
Build a separate module for non-regression optimization tests. This benchmark will increase its data set all along with the project life cycle. It will mainly measure the stability (or the improvement) of the optimization and/or business key performance indicators. Whenever the benchmark worsens quality, it shall be considered as a high priority warning that something is probably wrong in the latest code, including third party library updates.
Build a dashboard that monitors the main benchmark statistics (number of instances solved, average gap …).
Inject a solution
Provide a tool and an API to load an external solution. This enables us to challenge natural wonders such as “if I swap machines of activity 1 and activity 2, I should get a better solution”. Such local improvement guesses are quite natural to express but slightly more difficult to implement: they probably imply checking several constraints in cascade. As a consequence, a checker of this new solution needs to be launched to assert first the feasibility of the solution and then recompute the solution quality indicators to prove or reject the assertion that the move actually improves the current solution.
Note that this checker implementation can be either:
- Deterministic: we isolate a set of constraints to check (capacities, material flow balance…) and we recompute manually their satisfaction/dissatisfaction
- Through the optimization engine: the complete original solution plus the local modification suggested by the planner is injected in the solver model as additional constraints “Variable = value”. This is the most accurate checker since the first one may answer “check” letting some unchecked constraints unfeasible
Advice #6
Mix the suggested move with a constraint that states the improvement of the objective function: this eventually ends up in a conflict and provides a proof that the move is not improving the solution.
Conclusion
At DecisionBrain and in various places all over the world, the industry is consuming more and more of the techniques known as Operations Research (OR) to efficiently solve various organization challenges under resource constraints.
OR practitioners can efficiently play an important role in making very advanced mathematical techniques available for the benefit of organizations and planners. We hope that our various advices, tips and tricks will be valuable for the success of your next OR project!
Keep up to date with our blog
About the Author
David Gravot is a senior optimization dev at DecisionBrain. He has more than 20 years of experience as an Operations Research practitioner, focusing on Advanced Optimization engines and applications in manufacturing and resource planning.
Read also