Blog
Au-delà du Perroquet Stochastique : Construire une IA Responsable
1. Introduction
L’intelligence artificielle (IA) [eng. Artificial intelligence] peut-elle prendre des décisions fiables et explicables pour les entreprises ? Les entreprises et les services publics s’appuient sur des décisions précises pour les interactions avec leurs clients, l’éligibilité des produits ou services, la planification des effectifs et la logistique. Dans quelle mesure l’IA moderne soutient-elle cette prise de décision quotidienne qui est au cœur des opérations de chaque organisation ?
Les systèmes modernes d’IA générative (GenAI) [eng. Generative AI], tels que les large language models ( LLM) [fr. grands modèles de langages], semblent fournir des réponses sensées à de nombreuses questions, mais fonctionnent en exploitant des modèles statistiques plutôt qu’en comprenant véritablement le sens et en appliquant un raisonnement formel (Fig. 1). Ce phénomène, parfois appelé l’effet du « perroquet stochastique », souligne les limites de la confiance que l’on peut accorder à ces modèles dans des scénarios à fort enjeu.
Toutes les industries, de la santé à la finance, dépendent de plus en plus de l’IA pour la prise de décision, ce qui met en évidence l’urgence de reconnaître le potentiel de la GenAI ainsi que ses limites. Des techniques comme le Chain-of-Thought (CoT) [fr. chaîne pensée] et le Retrieval-Augmented Generation (RAG) [fr. génération augmentée de récupération] améliorent les résultats de l’IA, mais ne résolvent pas l’absence fondamentale de raisonnement véritable. Des approches hybrides combinant la GenAI avec des cadres décisionnels explicites – tels que les moteurs de règles, les outils d’optimisation et les simulations – offrent une voie vers des résultats plus fiables.
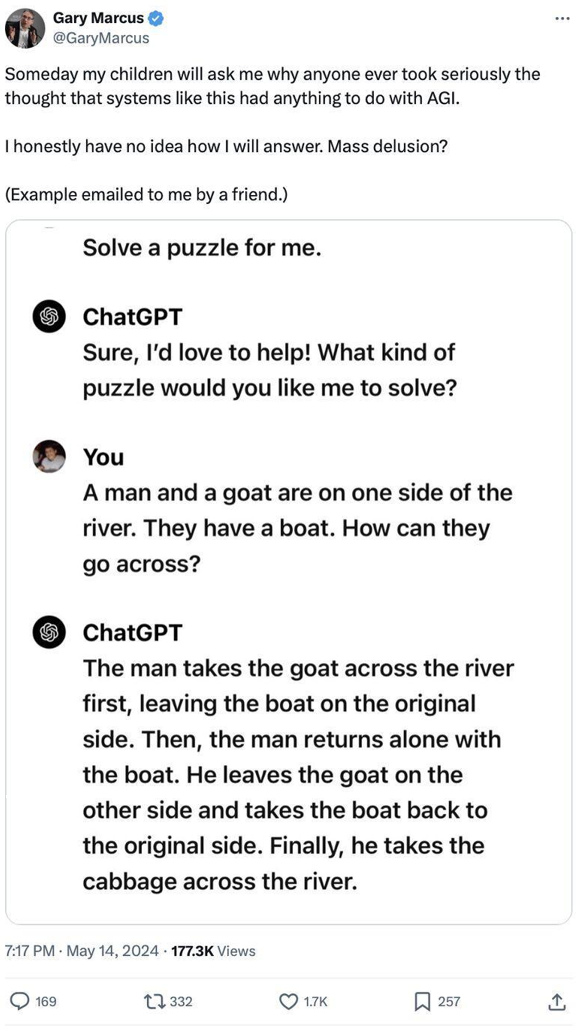
Fig. 1. GPT-4 imitant un schéma de raisonnement courant sans compréhension approfondie du problème [grâce à Gary Marcus].
2. L’IA générative et ses limites dans la prise de décision autonome
2.1 Le dilemme du « Perroquet Stochastique »
Les modèles de langage génératif fonctionnent en prédisant le mot suivant dans une séquence en s’appuyant sur des probabilités issues de vastes ensembles de données d’apprentissage. Cette approche probabiliste leur permet d’atteindre une fluidité linguistique impressionnante et de couvrir un large éventail de sujets. Cependant, ils souffrent d’une faiblesse majeure lorsqu’ils sont utilisés pour la prise de décision autonome. Bien que les LLM puissent sembler raisonner sur des tâches complexes, ils ne font en réalité que détecter des structures complexes dans les données au lieu d’appliquer une véritable compréhension ou un raisonnement structuré. Ils excellent dans la génération de réponses cohérentes en identifiant des corrélations linguistiques et conceptuelles dans d’immenses corpus textuels, mais ils n’ont pas la capacité de vérifier la justesse factuelle des informations ni d’interpréter le contexte de manière sémantique en appliquant des règles formelles ou en explorant un espace de solutions délimitées. Cette lacune devient particulièrement préoccupante lorsqu’il s’agit de décisions opérationnelles ou stratégiques nécessitant une expertise sectorielle approfondie, des considérations éthiques ou une stricte conformité réglementaire.
2.2 Hallucinations et sorties trompeuses
Les LLM ne peuvent pas garantir l’authenticité de leurs affirmations et inventent parfois des faits inexistants — un phénomène couramment qualifié d’« hallucination », mais qui pourrait être plus précisément décrit comme une « confabulation ». Ces productions trompeuses peuvent être particulièrement problématiques dans des domaines réglementés tels que la finance, les services publics, la santé, où une simple erreur peut entraîner des conséquences graves. Le style fluide et convaincant des réponses générées par la GenAI rend difficile pour les non-experts de repérer les inexactitudes, surtout lorsqu’ils ne disposent pas du contexte nécessaire. Comme les LLM sont conçus pour maximiser la probabilité de produire des textes cohérents et engageants, ils peuvent inventer des détails en l’absence de données corroborantes. Les utilisateurs risquent alors de s’appuyer involontairement sur ces informations erronées, augmentant ainsi le risque d’erreurs dans les décisions critiques.
2.3 Biais dans les données d’apprentissage
Comme toute technique d’apprentissage automatique, l’IA générative reproduit et amplifie les biais présents dans ses données d’entraînement. Avant même l’essor des LLM, des entreprises comme Amazon ont rencontré ce problème lorsqu’un modèle de recrutement basé sur l’apprentissage automatique a perpétué des discriminations de genre historiques. Même si des efforts sont faits pour purifier les ensembles de données ou ajuster les poids des modèles afin de corriger ces biais, de nombreuses corrélations problématiques restent profondément ancrées dans les vastes corpus d’apprentissage. Non seulement ces biais peuvent entraîner des décisions discriminatoires, mais ils exposent également les entreprises à des risques juridiques et réputationnels accrus, en particulier dans les juridictions appliquant des réglementations strictes en matière de lutte contre la discrimination. La supervision humaine et l’intégration de contraintes logiques explicites jouent un rôle crucial dans l’identification, l’évaluation et la correction de ces biais cachés avant qu’ils ne se traduisent par des décisions problématiques dans le monde réel.
2.4 Le problème de la boîte noire
Les moteurs de GenAI — et plus largement les modèles d’apprentissage automatique — fonctionnent généralement comme des « boîtes noires », offrant peu de visibilité sur leur raisonnement interne. Cette opacité nuit à la transparence et à la responsabilité, en particulier lorsque ces systèmes influencent des politiques organisationnelles ou des décisions ayant un impact significatif. De plus en plus de régulateurs exigent que les décisions prises par l’IA soient explicables et traçables : la législation européenne, par exemple, avec l’AI Act, impose des exigences documentaires pour les systèmes d’IA dits « à haut risque ». Les approches traditionnelles de l’apprentissage automatique — notamment le deep learning [fr. apprentissage profond] — sont particulièrement récalcitrantes à l’interprétation, car leurs pondérations internes ne correspondent pas directement aux concepts et mesures compréhensibles par les humains. Bien que certaines techniques d’« IA explicable » (XAI) permettent d’identifier des facteurs influençant une décision ou de tracer les grandes étapes du raisonnement, elles ne transforment pas une boîte noire en un système véritablement transparent. Ce défi complique à la fois la gouvernance interne et la conformité réglementaire, obligeant les entreprises à concilier le potentiel de la GenAI avec les exigences légales et éthiques en matière d’explicabilité.
En revanche, les technologies de raisonnement explicite, telles que les moteurs de règles et les systèmes à contraintes, permettent aux entreprises d’obtenir des explications claires basées sur des ontologies et des modèles formels — garantissant ainsi un niveau de responsabilité élevé. Toutefois, ces systèmes n’offrent pas les capacités linguistiques des LLM. Peut-être qu’une combinaison des deux approches pourrait être la solution idéale ? Nous reviendrons sur cette question plus tard.
2.5 Une dépendance excessive à l’IA
Un recours excessif à la GenAI peut éclipser des éléments essentiels tels que l’expertise humaine, le raisonnement éthique et la prise en compte du contexte spécifique. Les LLM sont performants pour synthétiser de grands volumes de texte et identifier des tendances générales, mais ils ne s’adaptent pas automatiquement aux évolutions réglementaires, aux changements des besoins commerciaux ou aux subtilités culturelles. Dans certains cas, des termes critiques présents dans des contrats ou des politiques d’entreprise nécessitent une modélisation explicite et un contrôle rigoureux des versions. Si ces aspects sont négligés et entièrement confiés à un LLM, des erreurs aux conséquences majeures peuvent survenir. Par ailleurs, les experts du domaine restent indispensables pour apporter une conscience situationnelle et s’assurer que les résultats générés par l’IA sont alignés avec les objectifs de l’entreprise, les contraintes légales et les impératifs éthiques.
2.6 La gestion du changement
Le monde évolue constamment : de nouvelles lois et réglementations apparaissent, de nouveaux produits sont mis sur le marché, de nouveaux concurrents modifient les dynamiques commerciales, nécessitant des ajustements dans les stratégies d’engagement client et les opérations. Or, les modèles d’IA entraînés sur des données historiques peuvent être dépassés lorsque l’environnement change de manière significative. Les exemples sur lesquels ces modèles ont été formés deviennent alors obsolètes, et il peut falloir des mois pour constituer de nouveaux ensembles de données d’apprentissage — un délai bien trop long pour répondre efficacement aux transformations du marché. Pire encore, si des systèmes automatisés continuent à utiliser d’anciens modèles, il peut devenir impossible de générer des exemples représentatifs des nouvelles règles ou situations. Dans de tels cas, une représentation explicite des règles et procédures du monde réel, accompagnée d’une gouvernance robuste, est nécessaire pour garantir l’adaptabilité et la pertinence des décisions.
3. Améliorer le raisonnement de l’IA avec des techniques avancées
3.1 Chain-of-Thought (CoT) et Tree-of-Thought (ToT)
L’approche Chain-of-Thought (CoT) oblige un modèle à expliciter les étapes intermédiaires avant d’arriver à une conclusion, ce qui peut potentiellement réduire les erreurs en rendant le processus de raisonnement plus transparent. La méthode Tree-of-Thought (ToT) va plus loin en explorant plusieurs enchaînements candidats en parallèle, bien que cette approche augmente la charge de calcul. Si ces techniques améliorent la clarté des réponses du modèle, elles ne garantissent toutefois pas une exactitude logique ou factuelle. Les LLM restant dépendants de leurs données d’entraînement et de leur architecture initiale, peuvent continuer à produire des raisonnements erronés si la question posée implique des contraintes nouvelles ou une logique complexe absente des motifs connus.
Bien que ces techniques augmentent considérablement les capacités de raisonnement des modèles, elles ont un coût. Le recours récursif à un LLM, en particulier pour les workflows CoT ou ToT, accroît la consommation de ressources informatiques, ce qui se traduit par une augmentation de la consommation énergétique et des coûts d’utilisation des API. De plus, ces méthodes peuvent amplifier l’impact des hallucinations : en réinjectant les résultats d’inférences précédentes dans le modèle, toute erreur initiale risque d’être propagée et intégrée dans la chaîne de raisonnement.
3.2 Retrieval-Augmented Generation – RAG
Le Retrieval-Augmented Generation vise à remédier au problème des connaissances obsolètes ou incomplètes des modèles en intégrant des sources de données externes au moment de l’inférence. Plutôt que de s’appuyer uniquement sur ses paramètres pré-entraînés, une application qui interagit avec un LLM peut d’abord consulter une base de données, un moteur de recherche ou un référentiel de connaissances pour enrichir le contexte fourni au modèle dans son prompt. Cette méthode permet d’atténuer certaines hallucinations en intégrant des faits mis à jour ou propres à un domaine spécifique.
Cependant, si le système de récupération d’informations ne parvient pas à localiser tous les documents pertinents ou s’il échoue à distinguer le contenu critique des informations superflues, l’IA peut toujours générer des réponses incomplètes ou incorrectes. Une mise en œuvre efficace du RAG requiert donc de bonnes métadonnées, des bases de données bien organisées, des algorithmes de recherche et d’indexation robustes.
3.3 Appels de fonction et workflow agentiques
Les appels de fonction et les workflows agentiques intègrent les LLM à des API externes ou à des graphes de tâches spécialisées. Cette approche permet aux systèmes d’IA de consulter des services à jour, d’effectuer des calculs spécifiques ou de vérifier certains faits. Par exemple, un LLM peut interroger un service météorologique ou un système de gestion de stocks en temps réel au lieu de s’appuyer sur des données périmées de son entraînement.
Les workflows agentiques automatisent les processus en déléguant des tâches à différentes entités (moteurs de règles, appels LLM, applications métier spécifiques). Toutefois, une gouvernance rigoureuse est essentielle : si les contraintes ne sont pas bien définies ou si l’IA dispose d’une trop grande autonomie, des résultats inattendus peuvent survenir, entraînant des risques en matière de sécurité ou de responsabilité légale.
Cette capacité est particulièrement prometteuse. La possibilité d’identifier et d’appeler des services externes ouvre la voie à la création de systèmes hybrides combinant la puissance linguistique des LLM avec des technologies de prise de décision plus précises et explicables, telles que les moteurs de règles et les outils d’optimisation. Nous verrons dans la section suivante comment ces approches hybrides peuvent être mises en œuvre pour offrir une prise de décision IA fiable et responsable.
4. Approches hybrides d’IA pour une prise de décision fiable
4.1 Intégration de l’IA générative avec des modèles décisionnels
Étant donné que la GenAI seule peine à garantir la fiabilité factuelle, l’explicabilité et la sensibilité au contexte, de nombreuses organisations adoptent des stratégies hybrides combinant les capacités des LLM avec des moteurs de logique structurée, des outils d’optimisation ou des systèmes de simulation. Dans une telle architecture, la GenAI excelle dans l’analyse des entrées non structurées – par exemple, en résumant des documents juridiques ou en extrayant des références politiques pertinentes. Une fois ces données structurées, des modèles explicites tels que les systèmes de gestion de règles métier (BRMS) [eng. business rule management system] et les moteurs d’optimisation mathématique appliquent des contraintes vérifiées et des critères de performance. Cette approche hybride empêche les sorties « stochastiques » d’un LLM de supplanter les impératifs légaux ou éthiques et permet aux experts métiers d’adapter les règles aux évolutions réglementaires, aux priorités stratégiques ou aux conditions du marché.
4.2 Exemple illustratif : Gestion des sinistres en assurance
Une compagnie d’assurance pourrait utiliser un LLM pour analyser des rapports d’incidents liés à des dégâts des eaux, en extrayant des détails tels que les numéros de police, les périodes, et les descriptions des dommages. Le LLM transmet ensuite ces résultats structurés à un moteur de règles qui détermine l’éligibilité et les paiements recommandés en fonction des conditions du contrat, des antécédents du demandeur et des réglementations locales. Si le LLM tente d’introduire des informations extrinsèques ou spéculatives – en imaginant, par exemple, une couverture qui n’existe pas – le moteur de règles annulera ces informations, garantissant que la décision finale s’aligne sur les directives vérifiées. En combinant une supervision humaine et des règles métier explicites avec les capacités d’extraction de données des LLM, les assureurs bénéficient d’un traitement des réclamations plus rapide sans compromettre la cohérence, l’explicabilité ou la conformité.
Lorsqu’il s’agit d’interactions clients concernant les réclamations d’assurance, une approche hybride peut également être utile (Fig. 2-3) :
- Les e-mails ou messages des clients peuvent être interprétés par un LLM pour déterminer leur intention et extraire les informations clés.
- Les appels à des outils et l’utilisation de RAG peuvent enrichir ces informations avec des données issues d’un système d’assurance central et d’un logiciel de Customer Relationship Management (CRM) [fr. gestion de la relation client] afin de fournir un contexte complet. Ces données peuvent également inclure des informations de segmentation client et des scores générés par des modèles d’apprentissage automatique.
- Ces données contextuelles peuvent ensuite être données à un système basé sur des règles pour garantir la conformité avec les politiques d’entreprise sur la manière de gérer les clients, notamment des règles sur le traitement différencié pour divers segments de clientèle tout en assurant à la fois réactivité et rentabilité.


4.3 Exemple illustratif : Analyse « What-If » de scénarios en modélisation de la chaîne d’approvisionnement – analyse par scénarios alternatifs
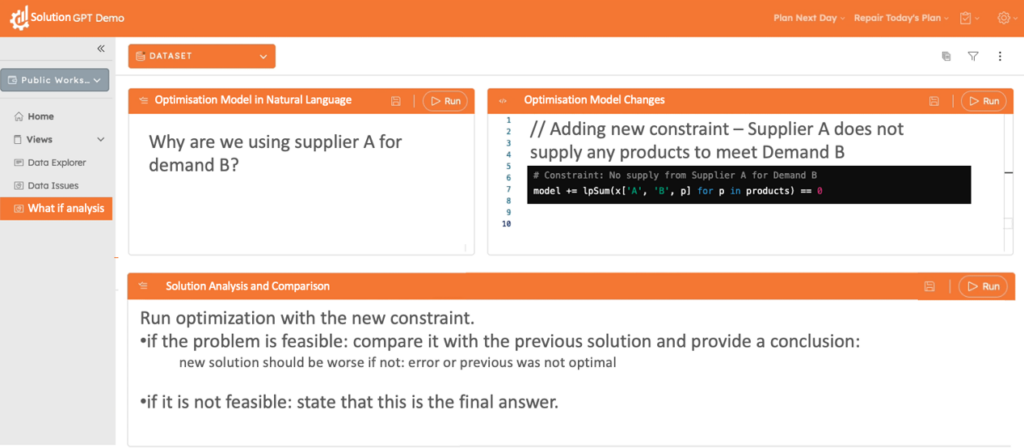
La figure 4 illustre comment une interface pilotée par un LLM permet aux utilisateurs non techniques d’explorer des scénarios « What-If » dans un modèle d’optimisation. Par exemple, un utilisateur peut poser une question en langage naturel – « Pourquoi utilisons-nous le fournisseur A pour répondre à la demande B ? » – et le système traduit cette requête en une contrainte symbolique qui interdit à A de satisfaire B, puis relance le solveur pour générer une solution alternative.
Si le problème est faisable, le système compare la nouvelle solution à l’ancienne, met en évidence les compromis et présente des explications concises en langage compréhensible. En revanche, si aucune solution n’est trouvée, le système signale clairement cette impossibilité, assurant ainsi une transparence totale quant aux contraintes décisionnelles. En combinant l’analyse des requêtes en langage naturel avec des techniques d’optimisation formelle, ce type de workflows permet aux décideurs d’explorer des alternatives et d’adapter leurs décisions sans nécessiter d’expertise technique avancée.
5. Avantages de l’IA générative dans la prise de décision
L’IA générative apporte de nombreux avantages lorsqu’elle est utilisée en complément d’outils de décision structurés. Les modèles peuvent analyser des données textuelles ou visuelles non structurées — des courriels aux contrats en passant par les contenus générés par les utilisateurs — et en extraire des informations essentielles et structurées. Cela accélère des processus comme l’étude de marché, l’analyse de la concurrence et le contrôle qualité, libérant ainsi les employés de tâches fastidieuses de lecture et de synthèse.
Elle démocratise également l’accès à la prise de décision basée sur les données en proposant des interfaces conversationnelles simples, accessibles même aux non-techniciens. Dans le domaine du développement logiciel, les LLM peuvent suggérer des extraits de code, mettre à jour la documentation ou générer des cas de test, accélérant ainsi le prototypage et réduisant les tâches répétitives.
Lorsqu’elle est intégrée efficacement, l’IA générative amplifie l’expertise humaine en extrayant des informations structurées de données brutes, en mettant en évidence des faits et des tendances pertinents, et en permettant aux professionnels de se concentrer sur des tâches plus complexes nécessitant jugement, créativité ou empathie. Par exemple, un système peut détecter des conflits juridiques potentiels dans un contrat qu’un professionnel débordé aurait pu manquer, tout en laissant la décision finale entre les mains des experts humains, avec des vérifications logiques explicites. Cette synergie permet aux organisations de tirer parti des capacités de détection de motifs de l’IA tout en garantissant sécurité, équité et conformité.
6. Conclusion
L’IA générative a démontré un potentiel considérable, notamment dans le traitement et la génération de données non structurées telles que du texte ou des images, et peut être considérée comme un ingrédient clé dans la transformation des processus décisionnels dans de nombreux secteurs. Tout au long de cet article, nous avons exploré comment l’IA générative peut améliorer la prise de décision en réduisant les biais humains et les erreurs, en accélérant les processus, en démocratisant l’accès aux données pour les non-techniciens et en stimulant la créativité et l’innovation. Ces bénéfices soulignent son aptitude à compléter et renforcer les capacités humaines, rendant ainsi les organisations plus efficaces et performantes.
Cependant, l’IA générative seule présente des limites importantes. Son fonctionnement basé sur des modèles statistiques sans compréhension réelle signifie qu’elle ne peut pas garantir des décisions pleinement conformes, en particulier dans des contextes commerciaux stratégiques. Pour pallier ces insuffisances, des approches hybrides combinant la GenAI avec des systèmes décisionnels symboliques — tels que les moteurs de règles, les outils d’optimisation et de simulation — offrent un cadre robuste pour des décisions fiables et traçables.
La collaboration entre l’IA générative, ces systèmes explicites et la supervision humaine met en lumière l’importance du partenariat humain-IA. Les humains fournissent la supervision essentielle, l’interprétation contextuelle et les considérations éthiques nécessaires, garantissant que les décisions assistées par IA restent précises, équitables et adaptées aux spécificités du domaine. Cette relation symbiotique est cruciale pour naviguer dans la complexité de la prise de décision moderne, en exploitant à la fois l’intelligence humaine et la puissance de l’IA pour créer des systèmes véritablement responsables et performants.
Lectures complémentaires
Voici quelques articles et publications que nous avons trouvés particulièrement intéressants pour mieux comprendre les défis et le potentiel de l’utilisation de l’IA générative et des techniques symboliques afin de rendre les systèmes d’IA plus responsables et performants.
- Syed Ali. ‘GenAI: The Future of Decision Making.’ LinkedIn, 2024. https://www.linkedin.com/pulse/genai-future-decision-making-syed-ali-gb4pc
- Yuhang Wang, et al. ‘Machine Learning and Information Theory Concepts towards an AI Mathematician.’ arXiv preprint arXiv:2403.04571v1, 2024. https://arxiv.org/html/2403.04571v1
- Emily M. Bender, et al. ‘On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?’ Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, 2021. https://dl.acm.org/doi/pdf/10.1145/3442188.3445922
- King & Wood Mallesons. ‘Risks of Gen AI: The Black Box Problem.’ King & Wood Mallesons, 2024. https://www.kwm.com/au/en/insights/latest-thinking/risks-of-gen-ai-the-black-box-problem.html
- University of Michigan-Dearborn. ‘AI’s Mysterious Black Box Problem Explained.’ University of Michigan-Dearborn News, 2024. https://umdearborn.edu/news/ais-mysterious-black-box-problem-explained
- John Smith, et al. ‘Explainable AI – XAI.’ arXiv preprint arXiv:2404.09554v1, 2024. https://arxiv.org/html/2404.09554v1
- Forbes Technology Council. ‘Decision Making 2.0, Powered By Generative AI.’ Forbes, February 14, 2024. https://www.forbes.com/councils/forbestechcouncil/2024/02/14/decision-making-20-powered-by-generative-ai/
- DecisionSkills.com. ‘Decision Making and Generative AI: Benefits and Limitations.’ DecisionSkills.com, 2024. https://www.decisionskills.com/generativeai.html
- Harvard Business Review. ‘How AI Can Help Leaders Make Better Decisions Under Pressure.’ Harvard Business Review, October 2023. https://hbr.org/2023/10/how-ai-can-help-leaders-make-better-decisions-under-pressure
- World Economic Forum. ‘Causal AI: The Revolution Uncovering the ‘Why’ of Decision-Making.’ World Economic Forum, April 2024. https://www.weforum.org/agenda/2024/04/causal-ai-decision-making/
- Diwo.ai. ‘What are the Differences Between Generative AI and Decision Intelligence?’ Diwo.ai, 2024. https://diwo.ai/faq/generative-ai-vs-decision-intelligence/
- Pierre Feillet. ‘Approaches in Using Generative AI for Business Automation: The Path to Comprehensive Decision Automation.’ Medium, August 4, 2023. https://medium.com/@pierrefeillet/approaches-in-using-generative-ai-for-business-automation-the-path-to-comprehensive-decision-3dd91c57e38f
- Rob Levin and Kayvaun Rowshankish. ‘The Evolution of the Data-Driven Enterprise.’ McKinsey & Company, July 31, 2023. https://www.mckinsey.com/capabilities/mckinsey-digital/our-insights/tech-forward/the-evolution-of-the-data-driven-enterprise
- Philip Meissner and Yusuke Narita. ‘How Artificial Intelligence Will Transform Decision-Making.’ The Choice by ESCP, December 5, 2023. https://thechoice.escp.eu/tomorrow-choices/how-artificial-intelligence-will-transform-decision-making/
- McKinsey & Company. ‘Artificial Intelligence in Strategy.’ McKinsey & Company, January 11, 2023. https://www.mckinsey.com/capabilities/strategy-and-corporate-finance/our-insights/artificial-intelligence-in-strategy
- Business Reporter. ‘Why Generative AI Is the Secret Sauce to Accelerate Data-Driven Decision-Making.’ Bloomberg, 2024. https://sponsored.bloomberg.com/article/business-reporter/why-generative-ai-is-the-secret-sauce-to-accelerate-data-driven-decision-making
- Runday.ai. ‘Can Generative AI Make Independent Decisions?’ Medium, July 12, 2024. https://medium.com/@mediarunday.ai/can-generative-ai-make-independent-decisions-d20db8412151
- Nelson F. Liu, et al. ‘Lost in the Middle: How Language Models Use Long Contexts.’ arXiv preprint arXiv:2307.03172, 2023. https://arxiv.org/abs/2307.03172
- Emily M. Bender, Timnit Gebru, Angelina McMillan-Major, and Shmargaret Shmitchell. ‘On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?’ Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, 2021. https://dl.acm.org/doi/pdf/10.1145/3442188.3445922
- Rossi F. and Mattei M. ‘Building Ethically Bounded AI’ arXiv preprint arXiv: 1812.03980, 2018. https://arxiv.org/abs/1812.03980

Filippo Focacci
Co-fondateur & PDG, DecisionBrain
À propos de l’auteur
Avant de fonder DecisionBrain, Filippo Focacci a travaillé pour ILOG et IBM pendant plus de 15 ans. Il a occupé plusieurs postes de direction dans les domaines du conseil, de la R&D, de la gestion et du marketing produits dans le domaine de la chaîne logistique et de l’optimisation. Il a obtenu un doctorat en recherche opérationnelle (RO) à l’université de Ferrare (Italie) et possède plus de 15 ans d’expérience dans l’application des techniques RO à des applications industrielles dans plusieurs domaines d’optimisation. Il a publié des travaux sur la chaîne d’approvisionnement et l’optimisation dans plusieurs conférences et revues internationales. Vous pouvez contacter Filippo à : [email protected]

Kajetan Wojtacki
Ingénieur de Recherche Senior, DecisionBrain
À propos de l’auteur
Kajetan Wojtacki est ingénieur de recherche senior chez DecisionBrain (depuis 2022), spécialisé dans le développement Python, l’intelligence artificielle et l’apprentissage automatique. Il possède une vaste expérience en calcul intensif, en modélisation numérique et en data-driven analysis, reliant des disciplines telles que la physique, la mécanique, la biologie et la data science. Auparavant, il a travaillé à l’Académie polonaise des sciences et au CNRS, participant à des projets multidisciplinaires appliquant la modélisation analytique et numérique ainsi que l’apprentissage profond. Kajetan est titulaire d’un BEng et d’un MEng en physique appliquée de l’Université de Technologie de Gdansk, ainsi que d’un doctorat en mécanique et en génie civil de l’Université de Montpellier. Vous pouvez contacter Kajetan à : [email protected]

Harley Davis
Fondateur & PDG, Athena Decision Systems
À propos de l’auteur
Harley Davis est un leader dans le domaine de la décision basée sur l’IA depuis 35 ans. En tant que responsable produit pour IBM Decision Management et IBM watsonx Orchestrate, Harley a dirigé la création de la nouvelle génération d’IA symbolique. En tant que responsable de la R&D d’IBM France, Harley a établi des partenariats étroits avec des universités et des chercheurs de premier plan en IA. En tant que responsable des ventes et des services professionnels chez ILOG et IBM, Harley a contribué à définir et créer le marché de la technologie des règles d’entreprise et a travaillé avec des dizaines d’entreprises de premier plan pour mettre en œuvre des systèmes de prise de décision. Harley est titulaire d’un BS et d’un MS du MIT en intelligence artificielle et en informatique. Vous pouvez contacter Harley à : [email protected]
Lire aussi